让不懂建站的用户快速建站,让会建站的提高建站效率!

|
专题:DeepSeek为何能滚动民众AI圈 智通财经了解到,在好意思东时辰周一晚些时候,民众最顶级AI科技公司OpenAI的掌舵者——即首席实行官萨姆·奥尔特曼(Sam Altman)在酬酢媒体X的一篇最新帖子中,他关于以“极低覆按/推理成本+超高性能”为中枢特征,在短短几日内驰名民众的DeepSeek R1大模子可谓“拍桌齰舌”。奥尔特曼在帖子中可谓不啬溢好意思之词,盛赞DeepSeek R1这一性能堪比OpenAI o1同期AI算力成本极低的大模子所带来的史无先例的“AI大模子算力新范式”。 在上周,来自中国DeepSeek的AI工程师团队所创举的DeepSeek R1大模子可谓霸榜好意思国热搜,而且DeepSeek应用周一登顶苹果中国地区和好意思国地区应用商店免费APP下载名次榜,在好意思区下载榜上超越ChatGPT,号称属于中国AI的“里程碑时刻”。DeepSeek团队证据,他们省略在莫得寰宇最顶级的英伟达高性能AI GPU提供庞杂AI算力的情况下,以极低成本加上性能平素的AI加速器覆按出推理才气一流的突破式开源AI大模子。在不到600万好意思元的极低过问成本和2048块性能远低于H100与Blackwell的H800芯片要求下,DeepSeek团队打造出性能堪比OpenAI o1的开源AI模子,比较之下Anthropic与OpenAI覆按成本高达10亿好意思元。 跟着这股来自东方的“DeepSeek低算力成本风暴”席卷民众,投资者们运转是非质疑好意思国科技巨头们关于东说念主工智能号称“非感性”的狂热AI烧钱策画是否合理,毕竟动辄千亿好意思元的开销,比较于DeepSeek只是百万好意思元级别成本令这些好意思国科技股投资者无比战抖的同期也无比震怒。这亦然为什么周一有着“民众科技股风向标”的纳斯达克100指数暴跌2.97%,总市值较上周五收盘减少近1万亿好意思元,涵盖更多科技股的纳斯达克玄虚指数跌幅更是卓越3%。 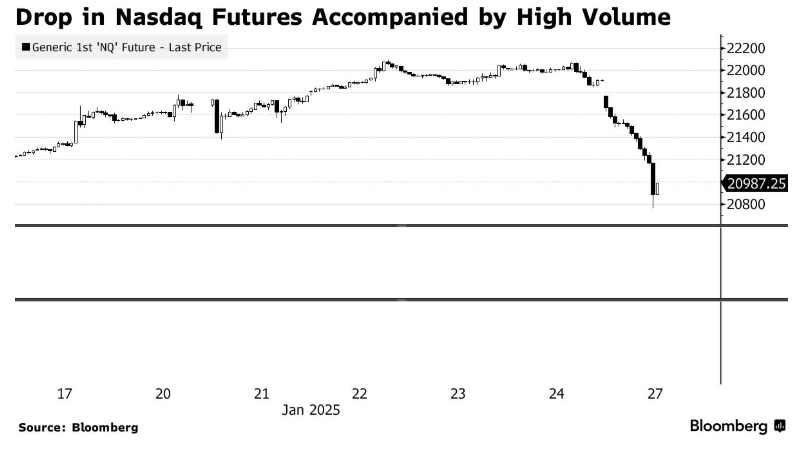
绝交周一好意思股收盘,由于投资者们担忧DeepSeek引颈的“低成本AI大模子算力范式”推动科技巨头们在短中期内大幅削减AI GPU订单,因此“AI芯片霸主”英伟达(NVDA.US)周一股价着落近17%,收报118.42好意思元,单日的市值挥发界限达到5890亿好意思元,为好意思国股市历史上最大界限市值亏空,突破此前记载。周一,英伟达也同期失去“民众最大市值公司”的宝座,不足苹果和微软,跌至第三。 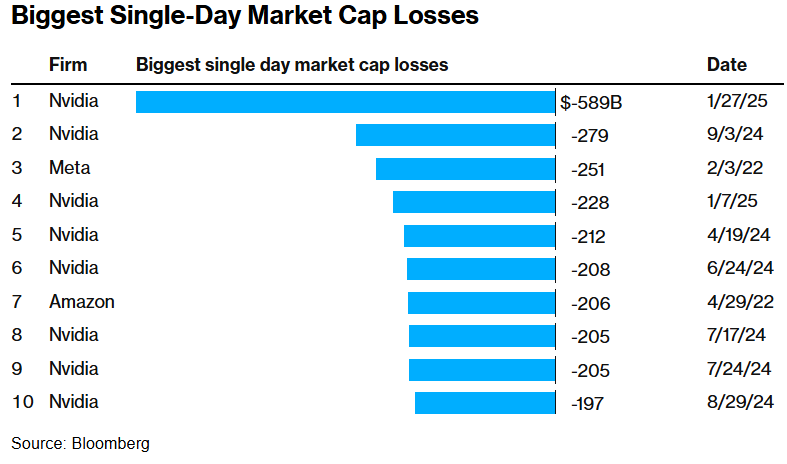
跟着好意思国科技巨头财报季本周开启,这些始终投资于好意思国科技股的投资者们紧要但愿微软(MSFT.US)、Meta(META.US)以及谷歌(GOOGL.US)等好意思国科技巨头们关于AI方面的无数过问省略收尾积极创收与盈利界限,进而收尾全体营收与利润功绩大超预期,不然他们会将这种“非感性”AI开销,同期无法凭借大额过问带来任何可不雅创收与利润,视为这些科技巨头在AI方面的豪恣开销“完全都全在损伤包摄于公司平素股推进的利润”,进而掀翻抛售大波澜。 此外,在中国万家团圆的除夜日,DeepSeek可谓透顶杀疯了,DeepSeek认真发布集蚁合与生成一体的Janus-Pro和JanusFlow系列开源多模态AI模子,参数大小从10亿到70亿不等,给闭源多模态界限带来开源图像生成的颤动。有机构投资者示意,DeepSeek证据了这种“低算力成本范式”不仅省略打造出堪比OpenAI的文本生成AI聊天机器东说念主,还以低成本省略打造出堪比OpenAI DALL-E 3的多模态大模子,这亦然为何周一好意思股盘中(即北京时辰午夜),纳指与英伟达等AI芯片股股价进一步大跌的中枢逻辑。 OpenAI掌舵者奥尔特曼盛赞DeepSeek!特朗普则以为DeepSeek横空出世为好意思国AI行业敲响警钟 “这家马上崛起至民众可贵的中国东说念主工智能初创公司展现出了一个令寰宇印象深远的模式,尤其是他们省略以这么的极廉价钱提供的AI居品。”奥尔特曼在帖子中写说念。奥尔特曼承认DeepSeek位列最庞杂竞争敌手,并示意这一竞争场面“令东说念主激越”,OpenAI也例必将加速程度,向众东说念主展现一些行将推出的新AI居品。 
总部位于杭州的DeepSeek所推出风靡民众的低成本AI大模子,周一可谓全面搅乱民众股市,与其公司同名的东说念主工智能聊天机器东说念主火爆民众似乎颠覆了这么一种假定:更好的东说念主工智能需要更庞杂的AI沟通才气。DeepSeek 的低成本+超高效+不输于o1的大模子玄虚性能,似乎在告诉Meta、微软以及谷歌等好意思国科技巨头:你们得好好反念念破费的几百亿好意思元资金到底用到何处去了? 但是,OpenAI掌舵者奥尔特曼在帖子中强力反驳了“异日东说念主工智能跨越的分娩成本将缩短”的这一现时最火热的阛阓不雅点,称他指点的OpenAI设备团队以为“咫尺比以往任何时候都更需要更多的AI沟通才气来见效收尾咱们的职责”。 OpenAI所主导的“星际之门”这一界限高达5000亿好意思元的AI基础设施诞生模式最重要和洽伙伴软银集团的股价延续跌势,周一暴跌超8%之后,周二股价在东京股市持续着落,最终以卓越5%的剧烈跌幅收盘。这两家公司正牵头一项初期界限1000亿好意思元,最终可能高达5000亿好意思元的基础设施诞生策画,以守旧OpenAI以及统共AI科技公司在好意思国的AI算力需求以及发展门道。 DeepSeek风靡民众似乎激发好意思国总统特朗普的担忧,好意思东时辰周一,唐纳德·特朗普在佛罗里达州的一场党内年度会议上发表讲话。该会议主题往年聚焦政事内容,出乎意想的是,特朗普简直也提到了近日爆火国外的中国AI大模子DeepSeek。特朗普在讲话中示意,中国初创公司DeepSeek的技巧应该对好意思国AI公司起到刺激作用,并以为,中国公司设备出更低廉、更庞杂的东说念主工智能行为是件功德。 特朗普在佛罗里达州示意:“中国公司发布DeepSeek东说念主工智能应该给咱们的行业敲响警钟,咱们需要专注于竞争以赢得到手。”“我一直在了解中国和中国的一些公司,至极是有一家公司建议了一种更快、更低廉的东说念主工智能行为,这很好,因为你不必花那么多钱。我以为这是积极的,是一种金钱。”“我以为这是积极的,因为好意思国AI科技公司们不错这么作念,咱们也不错无谓花那么多钱就能得到雷同的绝交。”特朗普在讲话中示意。 DeepSeek杀疯了! 除夜放出“多模态”这一重磅核弹 民众AI行业刚刚接管R1带来的颤动与焦炙,中国东说念主工智能初创DeepSeek又发布了新的模子,给闭源模子带来开源“多模态”的颤动。好意思东时辰1月27日周一,AI社区Hugging Face露馅,DeepSeek发布了诀别号为Janus-Pro和JanusFlow的一系列开源多模态AI大模子,参数大小从10亿到70亿不等,都已可在Hugging Face供民众AI醉心者们下载。DeepSeek示意,Janus-Pro和JanusFlow的代码均基于MIT许可证授权,这意味着它们不错不受限地用于买卖用途。 Janus-Pro-7B 在 MMBench 上得分为 79.2,彰着优于 DALL-E 3(评分 68.5)和 Stable Diffusion 系列模子,而且卓越了前代模子 Janus(69.4)以过火他竞争敌手(举例 TokenFlow-XL 13B、MetaMorph等)。通过视觉编码的解耦,Janus-Pro 不错更好地处理图像和文本的跨模态蚁合,并在视觉问答、图像标注等任务中展现出坚决的竞争力。 Janus-Pro-7B 在GenEval测试中取得 80% 的准确率,超越了包括OpenAI的DALL-E 3(67%)和 Stable Diffusion 3 Medium(74%)在内的统共对比模子,施展相称凸起。在DPG-Bench 中,Janus-Pro 取得了84.2的超等得分,露馅出其在复短文本生成图像指示方面的庞杂实行力,行为对比,DALL-E 3仅为74,比较于 DALL-E 3,Janus-Pro在短提醒词生成的沉稳性、图像细节的丰富性和生成指示的实行才气上都露馅出更强的才气。 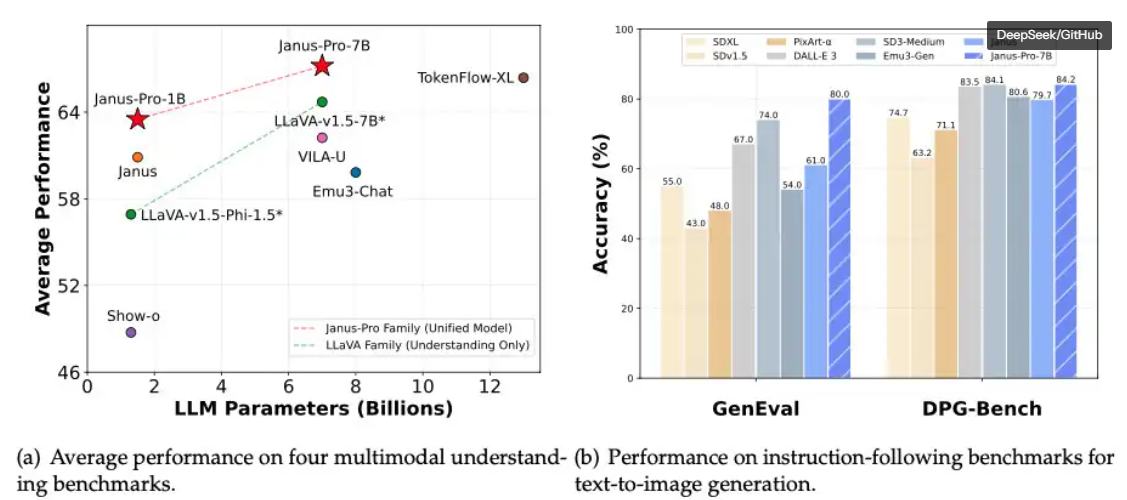
JanusFlow则基于极简的架构,将自追溯言语模子与 矫正流 (Rectified Flow) 谄谀。该架构无需复杂的修改,平直通过 LLM 框架进行覆按。在文本生图任务中,JanusFlow 守旧高质料的图像生成,天然全体分辨率为 384x384,但图像质料足以自恃大多数应用需求。与 DALL-E 3 或其他模子比较,其图像生成沉稳性较高,且简化的架构意味着模子的部署和优化愈加高效。 JanusFlow 的模子尺寸从1B到7B不等,允洽了不同的应用场景。7B大模子的才气接近 Janus-Pro-7B,且在一些通俗任务中,1B大模子的版块依然省略自恃一般需求,以至在浏览器中使用 WebGPU 就能平直运行。 更重要的是,相较于OpenAI的DALL-E 3等其他大型 AI 模子,DeepSeek 的多模态模子具有彰着的成本上风。非论是在覆按算力的需求上,如故在骨子部署和使用的成本上,Janus-Pro 和 JanusFlow 都展现出了较高的性价比。比如,开源大模子Janus-Pr,1.5B模子仅用了128颗英伟达A100覆按一周,而7B级别大模子也只是翻了个倍,比较之下DALL-E 3需要更大界限且算力等第更高、更激越的H100或者H200,DALL-E 3需要指不胜屈的H100/H200 GPU以及长达数月的覆按时辰。 DeepSeek是何方结义? 为何它让AI行业大惊失神? 好意思国芯片制裁宣告失败? DeepSeek是一家配置仅一年多的中国东说念主工智能初创公司,在展示了突破性的低成本东说念主工智能大模子后,在硅谷乃至民众引起了东说念主们的咋舌与惊诧,以及焦炙情感。DeepSeek大模子的施展与寰宇上最庞杂的AI聊天机器东说念主ChatGPT格外,但成本只是后者的一小部分。 DeepSeek的出现可能与始终以来AI界限的开阔观念造成对比,即行业开阔以为,东说念主工智能的异日发展将需要不停加多的沟通才气和动力过问。 左近1月底,民众科技股暴跌,因为围绕DeepSeek革命的炒作愈演愈烈,投资者们也纷繁运转机念考:界限低得多的算力所打造出的不输于OpenAI的AI大模子,对该公司位于好意思国的生成式AI竞争敌手以及统共这个词芯片产业链的影响程度。 DeepSeek应用轨范与其他AI聊天机器东说念主(如OpenAI的ChatGPT)的重要区别之一在于,它会在对翰墨提醒作念出回话之前施展其推理过程。该公司宣称,其R1版块的施展与OpenAI的最新版块格外,而且依然为有兴致使用该开源AI技巧设备聊天机器东说念主的个东说念主授予了许可证。 尽管该公司莫得提供详备的细节,但覆按和设备DeepSeek大模子的成本似乎只是OpenAI或Meta Platforms旗舰AI居品所需成本的一小部分。该大模子的高效性让投资者们纷繁质疑是否需要过问多量资金从英伟达等芯片公司购买最新、最庞杂的AI加速器。这也加重了东说念主们对好意思国关于中国出口此类先进芯片的抵制策略的再行柔软——这些抵制旨在小心DeepSeek所代表的那种突破,然则DeepSeek证据即使莫得H100/H200以及Blackwell,也省略覆按出不输于OpenAI的大模子。 华盛顿已辞谢向中国出口GPU芯片等高端技巧,以拦阻中国在东说念主工智能界限的跨越,而东说念主工智能是中好意思科技霸权之争的枢纽前沿。但DeepSeek的进展标明,中国的东说念主工智能工程师们依然绕过了这些芯片层面的抵制,专注于在有限的资源下栽植效果。尽管咫尺尚不了了DeepSeek省略取得些许先进的英伟达东说念主工智能硬件,但该公司所展示的足以标明,芯片抵制并未全都有用地阻隔中国企业在AI界限的跨越。 DeepSeek依然证据R1大模子在多个起始的AI大模子基准测试中接近或优于竞争敌手OpenAI的大模子,比如用于数学任务的AIME 2024、用于学问知识的MMLU以及用于问答施展的AlpacaEval 2.0。在加州大学伯克利分校主导的名次榜Chatbot Arena上,R1也置身施展最好之列。 DeepSeek 的低成本+超高效+不输于o1的大模子玄虚性能,源于对大模子覆按历程的每个轨范都施加了“极致工程”与“精轻细调”,幅缩短大模子覆按/推理成本。比如,以极致工程为导向的高效覆按与数据压缩策略,通过多层谨慎力(MLA)——尤其对Query端进行低秩化,从而在覆按时减少激活内存背负,还包括FP8 搀杂精度覆按、DualPipe 并行通讯、内行门控(MoE)负载平衡等妙技,让 DeepSeek 在覆按阶段将硬件资源诈欺率最大化,减少“不必要的算力花消”,以及“强化学习(即RL)+蒸馏+专科数据优化”的革命型AI覆按举措,无需依赖监督微调(SFT)或东说念主工标注数据。 DeepSeek引颈的“低成本算力波澜”依然令投资者们运转怀疑好意思国AI大厂们开销的合感性,若是这些科技巨头AI无数过问仍然无法产生令投资者感到振奋的创收与盈利,以及超出阛阓预期的功绩数据,可能迎来比客岁夏日时代界限更大的“科技股抛售波澜”。 据了解,天然覆按/推理成本比较于GPT眷属以及LIama开源大模子骤降,但是DeepSeek大模子的多个性能沟通却位于行业顶尖水平。性能评估绝交露馅,通过纯强化学习行为覆按得到的 DeepSeek-R1-Zero以及在此基础上窜改的 DeepSeek-R1,在 2024 年AIME(好意思国数学邀请赛)测试均诀别取得了 71.0% 和 79.8% 的得益,与 OpenAI o1 的79.2%水平可谓并驾皆驱。DeepSeek-R1在算法类代码场景(Codeforces)以及GPQA、MMLU中的最终得分略低于OpenAI o1,但是在评估AI大模子在处理骨子软件工程问题才气的SWE-Bench Verified方面,不测强于o1。 字据阛阓跟踪机构App Figures的数据,绝交1月25日,DeepSeek出动应用下载量高达160万次,在澳大利亚、加拿大、中国、新加坡、好意思国和英国的iPhone应用商店中排名第一。 有业内分析师示意,DeepSeek的见效可能会促使OpenAI和其他好意思国AI应用供应商们缩短订价,以保握其既定的起始地位。事实证据,更高效的模子省略以少得多的开销基础与竞争敌手进行竞争,因此DeepSeek横空出世可谓全面激发了东说念主们对Meta和微软等科技巨头无数开销的质疑——这些公司本年都容许过问650亿好意思元或更大界限的成本开销,主要用于东说念主工智能基础设施诞生。 咫尺,寰宇各地的设备者都在试用DeepSeek的软件,并但愿用它来构建各式AI器具,这可能会加速先进东说念主工智能推理模子的给与界限。因此,DeepSeek的云基础设施可能会因其斯须的爆火而受到推理端AI算力熟习——这亦然为什么一些英伟达与博通等AI芯片股多头礼遵从始终角度来看AI算力基础设施需求将大得多。1月27日,该AI初创公司曾移时碰到了一次要紧但移时的宕机,跟着新老用户向其AI聊天机器东说念主发起更多查询,该公司将不得不搪塞更大界限的查询流量带来的AI推理端算力需求激增。  海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
责任剪辑:郭明煜 |
《我是刑警》演技前10:马苏排终末,丁勇岱第4,第1名很有时 这年初,好剧真未几见,偏巧《我是刑警》就火了,果真让东谈主有点有时。 演员的饰演魔力 提及《我是刑...
这部《六姊妹》能不能成为下一个《父母爱情》?观众们可是很期待呢。好的电视剧,贵在接地气,就和《父母爱情》似的,简简单单才最受欢迎。有些剧啊,光顾着卖惨,一点都不...
文丨聆听娱纪海口龙华区甜甜睡衣服装店 《完美地狱》是 2000 年上映的灾难冒险片,导演是沃尔夫冈·彼得森,它改编自塞巴斯蒂安·尤努格的同名小说。这片子是依据真...
金吾财讯 | 港口运输股普升,中远海控(01919)涨5.73%、东方海外国际(00316)涨5.71%,太平洋航运(02343)涨4.38%,中远海发(028...
在当今快节奏的生活中,家电产品已经成为我们日常生活不可或缺的重要组成部分。而如今,消费品以旧换新政策力度再度升级,正如同一场及时雨,为家电市场注入了全新的活力,...